
Las copias de seguridad son una tarea fundamental que no podemos dejar de realizar ya que es vital poder tener un buen sistema de respaldo por si las cosas salen mal
A continuación te muestro un sistema de copias de seguridad, sencillo de implementar y muy barato, con el que podrás tener a salvo tus proyectos basado en Amazon S3.
Amazon S3 es un sistema de almacenamiento en la nube barato y que funciona realmente bien, puedes usarlo tanto si tus proyectos están alojados en Amazon como si no. El precio por GB de S3 es ridículo y sólo necesitarás tener una cuenta para empezar a disfrutar del servicio. Para que te hagas una idea, almacenar unos 50 GB te saldrá por poco más de 1$ al mes.
Configurar Amazon S3
Para usar el servicio deberás tener es una cuenta de Amazon y acceder a la consola de administración de Amazon Web Service (AWS).
Una vez dentro de la consola de Amazon, debemos crear un usuario con el que accederemos a nuestra cuenta, además haremos que este usuario solo tenga acceso a S3 para mayor seguridad. Para ello accederemos al servicio IAM y en el apartado usuarios crearemos uno nuevo añadiendo un nombre de usuario así como el tipo de acceso mediante programación.
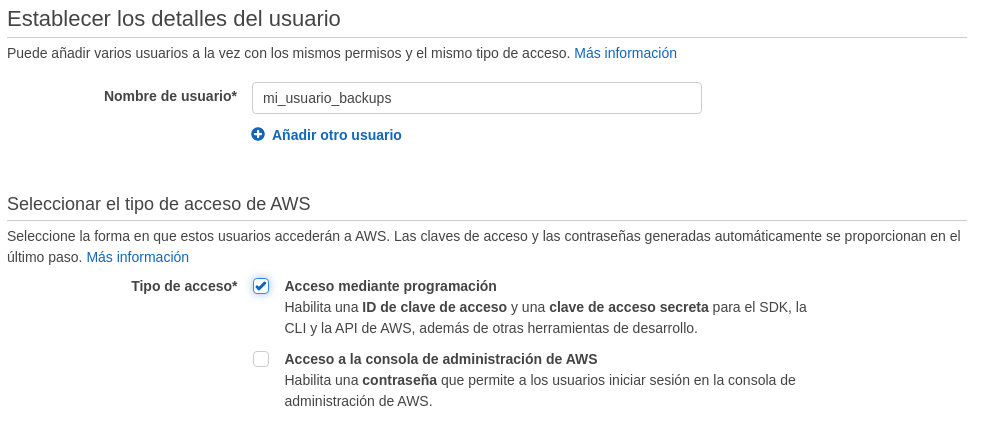
A continuación añadiremos los permisos que le daremos a el usuario. Para ello seleccionaremos el apartado Asociar directamente las políticas existentes y seleccionaremos AmazonS3FullAccess
Una vez creado el usuario, la consola nos mostrará un ID de clave de acceso y una clave de acceso secreta, guarda a buen recaudo estas credenciales, en poco tiempo la usaremos.

A continuación crearemos un bucket (contenedor de datos). El sistema nos pedirá los siguientes datos:
-
Añadir un nombre único y una región (centro de datos donde alojaremos los ficheros)
-
En ajustes de acceso de datos dejar marcado "Bloquear todo el acceso público"
-
Deshabilitar el control de versiones(no necesitaremos versiones de los ficheros, las manejaremos mediante el nombre de los ficheros)
-
Dejaremos desactivado el cifrado para poder obtener los ficheros con más agilidad, aunque puedes activarlos para añadir una capa más de seguridad a tus copias.
Una vez hagamos esto tendremos listo nuestro bucket para empezar a respaldar nuestros ficheros.
Configurar nuestro servidor
La forma más sencilla de acceder a los servicios de Amazon AWS es mediante su propio CLI. Con éste podremos configurar con apenas unas línea de comandos la subida de nuestras copias a Amazon S3
Partiremos que tu servidor es Linux, aunque si es MacOS o Windows también puedes instalarlo
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
$ unzip awscliv2.zip
$ sudo ./aws/install
En este punto ya tendremos nuestro CLI listo para empezar a usarlo, aunque antes tendremos que configurar el acceso a AWS S3. ¿Recuerdas las credenciales que creamos hace unos minutos? Ok, pues ya es hora de usarlo.
Además de estas credenciales, tendremos que recordar el nombre único del bucket que creamos y la región donde ubicamos el bucket
Ahora sí, configuremos nuestro CLI con los datos que previamente habíamos obtenido.
$ aws configure
AWS Access Key ID [None]: TU_ACCESS_KEY
AWS Secret Access Key [None]: TU_SECRET_KEY
Default region name [None]: TU_REGION
Default output format [None]: json
Esta configuración nos creará dos ficheros ubicados en la carpeta de nuestro usuario:
~/.aws/config :
Aquí se guardan las configuraciones de la región o el formato de salida
~/-aws/credencials:
En este fichero se guardará la información de nuestras credenciales de acceso
Fijate que en estos ficheros nos encontraresmos algo como [default]. Esto es así porque las credenciales las hemos guardado en el perfil por defecto. Si queremos tener más configuraciones podemos añadir un nombre de perfil en la configuración que podremos seleccionar cuando ejecutemos los comandos del CLI
$ aws configure --profile TU_PERFIL
Preparando las copias
Una vez tenemos configurado el CLI lo siguiente que tendremos que hacer es configurar nuestra copia de seguridad y enviarla a S3. Existen numerosas formas de hacerlo, creando copias incrementales, completas, etc. Para esto podríamos usar herramientas como rsync, pero nosotros vamos a crear copias de una forma mucho más sencilla. No obstante, te invito a que investigue como funciona rsync ya que te permitirá hacer copias más complejas.
Cuando queremos realizar un backup, normalmente necesitamos realizar copias de la base de datos por un lado y de los ficheros por otro.
Empecemos por la base de datos. Para este ejemplo, partiremos de una base de datos en MYSQL. Esta base de datos nos provee de un comando de consola que nos lo pone muy fácil.
Creemos un script mysql.sh en nuestro servidor con el siguiente código
START_TIME=$(date +%s)
DATABASE=database
ZIPNAME=database_$(date +\%s).zip
S3_BUCKET=s3://mibucket/databases/
PROFILE=default
echo "Dumpping database ..."
sudo mysqldump --single-transaction --quick --skip-extended-insert --routines -uroot $DATABASE | zip > ./$ZIPNAME
aws s3 cp $ZIPNAME $S3_BUCKET --profile $PROFILE
rm $ZIPNAME
END_TIME=$(date +%s)
echo "Time Elapsed: $(($END_TIME-$START_TIME)) seconds"%
Si te fijas en el código, la línea más importante es donde hacemos el mysqldump que es el comando que realizará la copia de seguridad y mediante un tunel comprimiremos en zip la salida del comando.
Una vez tenemos nuestro fichero zip, pasaremos a subirlo a Amazon S3 con el comando aws s3 cp donde le pasaremos el nombre del fichero que vamos a subir, el bucket donde alojaremos la copia en S3 y el perfil de configuración que usaremos para subirlo.
Las últimas líneas borran el ZIP que hemos creado de forma temporal e imprime por pantalla el tiempo que nos tomó realizar la copia de seguridad.
Una vez tenemos preparada la copia para la base de datos, es el turno de respaldar nuestros ficheros.
El script es muy similar al que hemos usado para la base de datos, con la salvedad que vamos a copiar más de un fichero. A nuestro script lo llamaremos files.sh.
En este punto, lo ideal es que solo copiemos todo aquello que no tengamos en nuestro repositorio para que las copias sean justo de aquello que no tenemos guardado en otro sitio, como ficheros alojamos por nuestros usuarios, etc.
START_TIME=$(date +%s)
BASE_PATH="/var/www/miweb/"
INCLUDES="$BASE_PATH/avatars $BASE_PATH/uploads $BASE_PATH/stuff"
ZIPNAME=files_$(date +\%s).zip
S3_BUCKET=s3://mibucket/files/
PROFILE=default
echo "Dumpping files ..."
zip -r $ZIPNAME $INCLUDES
aws s3 cp $ZIPNAME $S3_BUCKET --profile $PROFILE
rm $ZIPNAME
END_TIME=$(date +%s)
echo "Time Elapsed: $(($END_TIME-$START_TIME)) seconds"%
Básicamente lo que hacemos es crear un fichero ZIP con las carpetas que incluimos en la variable INCLUDES de manera recursiva.
Al igual que con el anterior script, usaremos aws s3 cp para subir nuestro ZIP a Amazon S3
Por último simplemente nos quedaría crear un par de cronjobs que nos ejecuten ambos ficheros de forma recurrente y ya tendremos nuestro sistema de backups a bajo coste